
本文摘自《Human-Computer.Interaction》第二章,作者:I. Scott MacKenzie,由江南大学设计学院研究生刘兆峰翻译。
2.4 反射
通过移动或运动控制,人类有能力去影响周围的环境。控制是通过反射产生的。无论是用手指发信息或指示方向,用脚走或跑,皱眉头,通过声音来说话,或身体靠着什么,运动为人类提供了参与和影响周围世界的力量。Penfield的运动侏儒对人类的反射做了一个经典的阐释(Penfield和Rasmussen,1990)。(见图2.9。)图示的区域展示了大脑皮层运动区与人体运动控制的对应关系。下方皮质区的长度对应控制每个肌肉群的反射状态。从反射弧长度可知,与手腕,肘部和肩膀的控制相比,肌肉对于手和手指控制具有更高的敏感性。基于这部分信息,Card等人(1991)认为,“如果我们想完成更加精细复杂的动作,那么这些与机体接收器相连的更大面积的肌肉群是值得关注的位置,” 虽然他们义正言辞地说,“肌肉性能的决定因素不在简单的皮质区,而是取决于别的更复杂的区域”( Card等人,1991,p. 111)。(参见Balakrishnan and MacKenzie,1997)
在本章的最后的学生练习2-1还将看到这方面的内容。
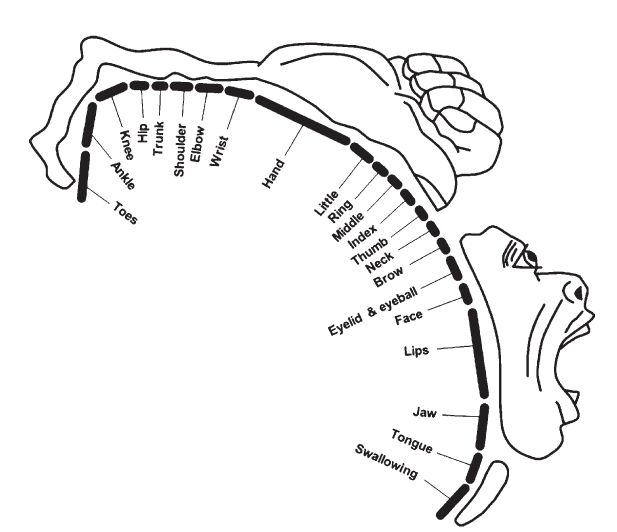
图2.9运动侏儒展示了人类运动神经反射和相应的皮质区的关系
(引自Penfield和Rasmussen,1990)
2.4.1 四肢
人类通常是利用四肢,特别是上肢来操控机器,在人机交互中也是一样的。用手指,手掌和手臂敲击键盘,滑动鼠标,按下按钮,握持手机按下按键,在触屏手机和平板表面触摸和滑动,在显示器前挥动游戏控制手柄。当然,腿和脚也可以完成对电脑信号的反馈和输入操作。对于上肢行动不便或残疾的用户来说,头部运动也可以控制屏幕上的光标移动。图2.10展示了一些这样的案例。
肢体的动作与体感系统是紧密耦合的,特别是本体感觉(本体是通过肌肉和肌腱的刺激来感知和协调肢体的运动和位置关系),以实现身体各部位间动作的精确和协调。最常见的例子就是人们在使用鼠标时视线并不是一直盯着鼠标,而且可以不看键盘进行盲打输入。
在图2.10a中,用户的左手握鼠标。大概这个用户是左撇子。图2.10b中,用户的右手食指与触控板的表面接触。据推测,这个用户是右撇子。有趣的是,左撇子,或手的优势,并不是一个非此即彼的状态。虽然人们认为群体中左撇子占了8%到15%,人们惯用某只手的现象在某种程度是一直延续和存在的。双手通用的人基本上对于左右手的使用没有特殊偏好。
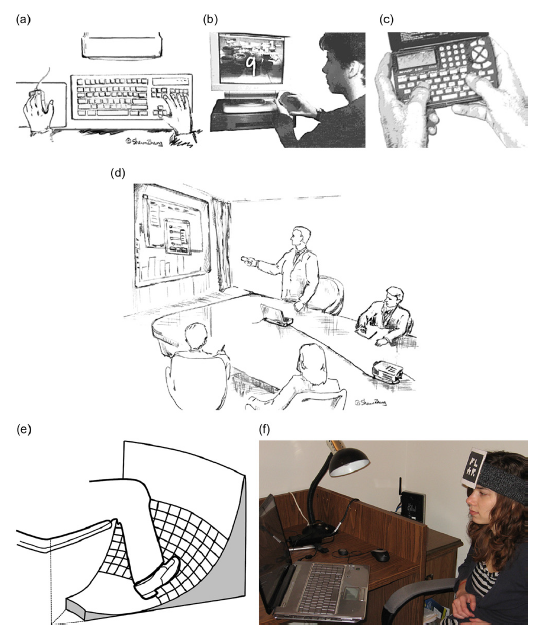
图2.10 在人机交互中使用四肢:(a)手掌(b)手指(c)拇指(d)前臂(e)脚(f)头
(草图a和d承蒙Shawn Zhang绘制;图e改编自 Pearson and Weiser,1986)
一种广泛使用的用来评估惯用手的工具是Edinburgh惯用手量表,这可以追溯到1971(Oldfield,1971)。量表由一系列的测试构成,通过执行像扔球这样的常见任务时的双手偏好程度让人们进行自我评估。量表如图2.11所示,随着指示进行,接下来是评分,解释结果。得分在−100到−40人是左撇子,而那些得分在+ 40到 + 100是右撇子。人评分−40 + 40则属于双手通用的人。

图2.11 Edinburgh堡惯用手量表为惯用手进行评估(Oldfield,,1971)
爱丁堡惯用手量表实验也给人机交互研究提供了一些案例(Hancock and Booth, 2004; Hegel, Krach, Kircher, Wrede, and Sagerer, 2008; Kabbash, MacKenzie, and Buxton, 1993; Mappus, Venkatesh, Shastry, Israeli, and Jackson, 2009; Masliah and Milgram, 2000; Matias, MacKenzie, and Buxton, 1996)。在某些情况下,“惯用手”的程度被记录下来。例如,Hinckley等人。(1997)在报告说道,在他们的研究中,所有的参与者都是“坚定的右撇子”,这在量表中的平均值为71.7。
惯用手往往与环境中的触摸或压力传感显示情况有关。如果交互操作需要记号笔或手指在显示器上进行,然后用户的手可能遮挡一部分显示内容。这种遮挡可能会导致较差的操作结果(Forlines and Balakrishnan,2008)或者用户扭曲手臂的位置摆出“钩形姿势”以便于交互操作的进行(Vogel and Balakrishnan, 2010)。这可以通过合理布局屏幕上不同区域的用户界面元素来避免(Hancock and Booth, 2004; Vogel and Baudisch, 2007)。当然,这需要检测或确定用户用手习惯,因为对于左撇子或右撇子来说遮挡结果是不同的。
2.4.2 声音
人是通过声带来发声应答的。通过咽喉喉头的运动,并在肺动脉压力的共同作用下,人类可以创造出各种各样的声音。声音的最明显的形式——说话——也是人类沟通的主要渠道。作为一种输入方式,说的话要通过算法在软件上运行,从而被主机识别。用这种方式,计算机就可以像键盘输入一样解释说出的话了。Vertanen和Kristensson(2009)描述了一套能够自动识别语音的移动文本输入系统。他们说坐姿状态下每分钟可录入18个字,行走状态下是每分钟13个字。
计算机输入也可以使用非语音录制的声音,这种方式也可称为非语言的语音交互(NVVI)。在这种情况下,不同的声音信号的声学参数,例如音调,音量,音色,是随着时间进度进行测量的,一条数据流被定义为一个输入通道。这种技术是在对指定参数的模拟方面作用十分明显。例如,一个用户可能说一句户,如“调高音量,啊~。” 用户只要一直保持“啊~”的状态,系统作为反馈,会增加电视的音量设置(Igarashi and Hughes,2001)。Harada等人(2006)描绘了一套声乐操纵杆系统——使用NVVI模拟操纵杆并控制屏幕上的光标(例如,“eee”=移动光标左)。这种应用程序对于没有创建允许用户选择手动访问计算内容的设计来说是很有用的。
2.4.3眼睛
在正常情况下,人的眼睛接收外环境以光的形式传播过来的感官刺激。观看周围环境的时候,眼睛采用注视的方式查看特定的地点,扫视时将目光移动到不同的位置。毋庸置疑,眼睛很早就被当作感觉器官了。然而,眼睛也能够承担响应器的任务——通过注视和扫视来控制计算机。想要具备这种能力,眼睛被需要承担双重职责,因为它这时需要既是一个感受器,同时也是一个响应器。这个想法如图2.12所示,展示了一个改进了的人机界面视图(参见图2.2进行比较)。从人到电脑的之间的交互路径改变了。不再是手通过操控物理设备从而控制计算机提供的运动反馈(灰色部分),眼球运动反应通过软控制——显示系统呈现的虚拟或图形控件来操作计算机。
对于用眼睛来实现计算机输入控制而言,眼球追踪装置需要感知眼球的关注点和移动轨迹,并将其进行数字数处理。眼动仪通常被用来作为模拟计算机鼠标的装置。和鼠标的点击选择操作很相似,眼睛可以实现观看选择,进而激活按钮、图标、链接或文本等控件(例如,Zhang and MacKenzie,2007)。眼睛最常见的选择控制方法是通过固定位置,或者,在一段预定的时间内悬停在一个可选择的目标上,例如静止750毫秒(程序可认为用户进行了选择)。
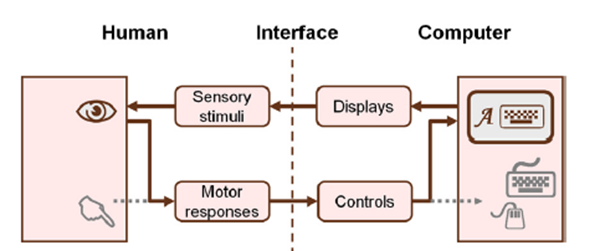
图2.12眼动仪的人机界面。眼睛需要处理双重任务,接收从计算机显示器传来的刺激,并对控制系统提供控制反应结果。
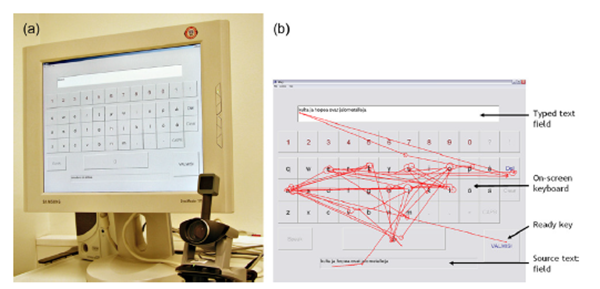
图2.13眼睛打字:(a)装置(b)的注视和扫视的示例序列(Majaranta等人,2006)
文本输入是眼动输入控制的一个应用。所谓的眼睛打字需要一块屏幕键盘。用户看着屏幕按键,在一段规定时间内让视线凝视在某个位置进行选择。图2.13a所示的是使用SensoMotoric仪器公司的iView X RED-III型眼动仪的一个例子(文本输入是眼动输入控制的一个应用。所谓的眼睛打字需要一块屏幕键盘。用户看着屏幕按键,在一段规定时间内让视线凝视在某个位置进行选择。图2.13a所示的是使用SensoMotoric仪器公司的iView X RED-III型眼动仪的一个例子(www.smivision.com)。图2.13b显示的是一名用户在输入一段短文本时的注视和扫视序列(扫描路径)((Majaranta, MacKenzie, Aula, and Räiha,2006)。直线代表扫视,圈表示凝视,圆圈直径表示凝视的持续时间。记住,这里所用的方法是有意识的有目的的控制计算机界面的行为。这不同于图2.7中所示的方法,那个图中其中用户只是在浏览网页内容。在图2.13b中,大量的凝视——这一交互行为只有满足程序所需的驻留时间时才能够成功地选择按键。当然这里的凝视也包括(与两次相应的扫视对应)查看键入的文本内容。
2.5大脑
大脑是最复杂的生物结构。由数十亿神经元构成的大脑让人类拥有了众多的能力和资源,包括思考,回忆,唤起,推理,判断和沟通。当感受器(人为输入)和反应器(人为输出)就是通过大脑从而相互连接起来的。在没有感知或体验外部环境时,大脑几乎什么都做不了。然而,一旦感受器开始感知体验环境,大脑的任务便开始了。
2.5.1 知觉
知觉,是大脑处理过程的第一个阶段,在收到从环境输入的感觉信号时激发。它处于感性加工阶段,逐渐形成关联和涵义的雏形。听觉刺激可分为和谐或不和谐。气味可分为愉悦或不一致。视觉场景可分为熟悉的或是陌生的。触摸的东西可能是表面光滑或粗糙,或热或冷的。随着关联和涵义的感觉输入,人类是远远优于与他们产生交互的机器:
感知、创新、超越所给的信息而使原本混乱事件的意义,这些都是人类所擅长的。我们要解释的事情经常是远远超出了身边可用的信息,但我们依然有能力这样做,并且做起来既有效率又毫不费力,通常甚至没有意识到我们都是这样做的,这也大大增加了我们这方面的能力。
(Norman, 1988, p. 136)
自十九世纪后期以来,知觉一直作为实验心理学中一个专门的学科领域——心理物理学中被研究。心理物理学研究的是人类感知和物理现象之间的关系。在心理物理学实验中,被试接受到一个物理刺激,然后被询问有何感觉或知觉。现实中的物理刺激刺的可测量特性结果与人主观感受的解码的现象的之间的具有一定的联系。一个常见的实验的目标测量刺激之间恰好能够感到明显差异(JND)数值。被试主观上一个接一个地受到两个刺激。刺激的物理性质是不同,例如两个频率或强度会有差异,然后询问被试感受到的刺激是相同的或不同的。实验的任务是重复一系列的实验,实验中各个刺激之间的物理性质差异的大小是随机变化的。当差异低于一定的阈值时,两个刺激之间的差异是很小,而此时主体也感知不到这种差异。这个阈值就是JND。各种情况下的所有人类感觉JND都已被深入研究过。JND取决于刺激的幅度等级吗(例如,高强度的刺激与低强度的刺激)?JND的属性(如强度)取决于第二属性的绝对值吗(如频率)? JND取决于年龄,性别,或其他人类属性吗?这些都是JND研究的基本问题,他们从表面上看,似乎与人机界面的你研究内容相差很远。但随着时间的推移,从以往的研究中延伸出的新的研究成果,能够很好地应用于人机交互中。例如,在心理物理学的基础研究可用于MP3音频编码的音频压缩算法中。
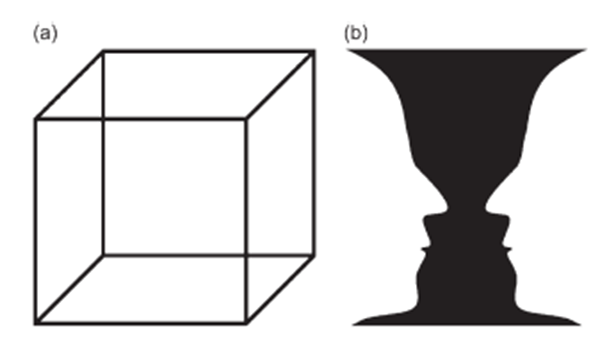
图2.14 引起歧义的图像:(a)Necker立方体(b)Rubin花瓶
另一个知觉属性是歧义——人类具有对接收感觉进行多重解释的能力。能够引起歧义的图像可以证明这种视觉能力。图2.14a展示的是Necker立方体显示线框。线框右上角代表了立方体的前表面还是后表面?图2.14b显示的是Rubin花瓶。图像是一只花瓶还是两张人脸?事实上,我们对这些图像中模棱两可的内容的认知,显示了我们具有感知超出图像所给信息的能力。
与引起歧义相关的是错觉,也就是通常认为的欺骗。图2.15a 中展示的是Ponzo线。两根黑色线的长度是相同的;然而,由于人类习惯的三维视角观看,因此图片底部的黑色线似乎要短一些。图2.15b展示的是Müller-Lyer箭头。在比较两个箭头的直线段长度,顶端的箭头似乎更长,但事实上两根直线长度相同。我们的直觉,背叛了我们。
如果在视觉刺激中存在错觉的可能,那么期望在其他感官中也存在错觉(的猜想)就是合理的。一个听觉错觉例子是Shepard音阶。人类知觉认为音节是不断地上升或下降的,但实际是音阶以某种方式保持不变。连续变化的是被称为Shepard-Risset 滑音的音调——音调不断上升变化的同时也继续保持在同一音调上。图2.16说明了这种错觉现象。每个垂直线代表一个正弦波。每一行的高度为正弦波的感知响度。每一个波又都会被相邻同频率的波所替代;因此,这种基本频率等于位移的波被称为谐波。这是一个能被人类感知的单一音调的频率波。如果正弦波的频率集体提升(图中箭头)的话,人们能感觉到音调上升。然而,由于正弦波是等距的,这种相互制约使音调听起来是相同的(因为谐波之间的频率通过距离感知的)。正弦波频率在顶部波峰逐渐淡化,而在底端波谷处产生新的正弦波。Shepard音阶的例子和Shepard-Risset滑音可以在YouTube上听到。
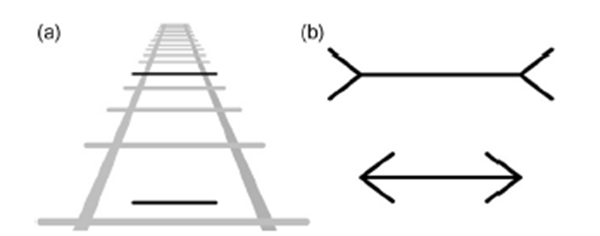
图2.15视错觉:(a)Ponzo线(b) Müller-Lyer箭头
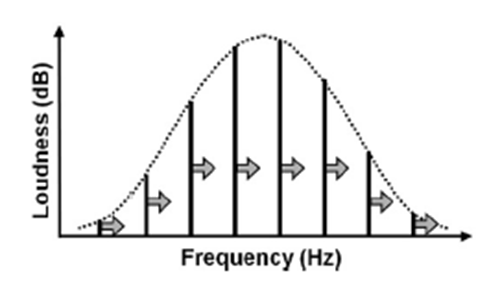
图2.16听觉错觉。一系列等距的正弦波频率的上升。人类听到音调升高但实际上是保持不变。
触觉或触觉错觉也存在。常见的例子是“幻肢”。进行过肢体的截肢的人仍会经常感觉到肢体的存在,它好像也可以像截肢之前的身体那样运动。(Halligan, Zemen, and Berger,1999)
超越感官刺激的感知整合成无数经验,进而产生想法,决策,策略,行动等等。能够掌握这些高级功水平的能力是推动人类站上生态系统顶端因素所在。人类的思考和推理的能力使我们能够在生物界保持这样的特殊的地位。
2.5.2认知
大脑的重要能力之一是认知——一种有意识的智力活动过程,如思维,推理和
决策。认知跨越许多领域——从神经学到语言学再到人类学——毫不奇怪,对于认知的范围存在许多不同的观点。认知是一种广泛性的社会化过程,还是一种更狭隘的刻意关注目标驱动的过程,例如解决问题这样的行为呢?阐明许多关于认知的观点超出了本书的范围。这个任务太伟大了,在任何情况下,文献都做了恰当的解释,许多内容都涉及到了人的因素。(例如H. Kantowitz and Sorkin,1983;Salvendy, 1987; Wickens,1987)
感觉现象如声、光容易研究,因为他们存在于物理世界。仪器可以记录和测量丰富的感觉信号。但认知产生在人类的大脑中,所以这就对研究认知提出了特殊的挑战。例如,我们是不可能直接测量出一个人作出决定的时间长短的。测量何时开始和结束?在哪个位置进行测量?依据什么输入形式进行决策?又通过什么样的输出形式传达决策?后两个问题讲的感官刺激和运动反射都可以归为认知操作这一类。图2.17a说明了这点。因为感觉刺激和运动反射可以被观察和测量,数据可以粗略的如何衡量一次认知过程。不过,这也有挑战。如果感官刺激的是视觉,视网膜将光转换为神经冲动传输到大脑进行知觉加工。这需要时间。这样的认知过程是何时开始的,我们无法准确知道。同样,如果运动反射是手指按下一个按钮,用于反射神经冲动在大脑传递给手运动开始的神经信号时就形成了。这样的认知操作的精确结果是未知的。这样一系列的事件如图2.17b所示,标出了操作过程以及每一步的典型时间。这里最引人注目的观测值的范围之广泛,以致确定在何处和如何进行测量的指示困难重重。尽管存在这些挑战,用于测量认知操作的技术一直存在。这些我们稍后再做讨论。
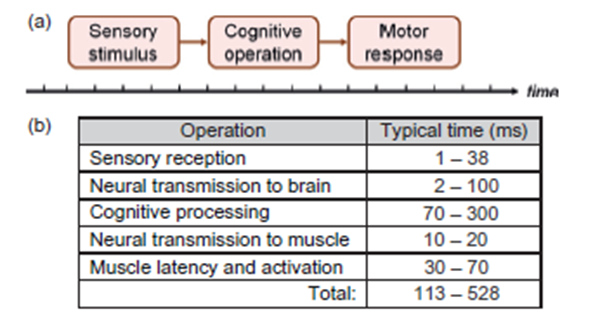
图2.17认知操作的反应时间任务:(a)严谨性问题(b)操作序列问题(Bailey,1996年,第41页)
图2.17的认知操作适用的范围很广。开车时,决定是在响应不断变化的光信号,松开制动踏板是很简单的。类似的情况在人机交互过程中比比皆是。使用手机时,你也许会决定按结束键拒接来电。早上在线阅读新闻的时候,可能会点击一个弹出广告关闭按钮;编辑文档的时候,可以在听到新消息提醒的时候切换到邮件。这些例子分别都包括感官刺激,认知操作和运动反射。
其他一些决策更加复杂。在玩纸牌游戏21点(又名黑杰克)的时候(也可能是在线玩),如果手牌总数是16,决定继续叫牌时可能产生一种认知的停顿。有多少可能下牌卡加起来点数会超过21?6到K的牌已经发了多少?显然,在这种情况下,决策超越了感官的刺激信息。有策略地去思考,也有能力记住和回忆之前已经发过多少牌。这种能力告诉我们大脑还有另一个主要功能——记忆。
2.5.3记忆
记忆是人类储存,保留和唤起信息的能力。我们的记忆能力是显着的。经历,无论是过去几天或几十年的信息,都集中在大脑的大容量存储库中,被称为长期记忆。有趣的是,大脑记忆和电脑存储记忆之间具有相似性。电脑记忆通常包括数据和代码的分区存储。在大脑中,记忆也是使用同样的组织方式。存在一个声明/明确的区域及时存储外部事件和对象物体信息。这类似于一个数据空间。大脑的隐式/程序区域记忆存储的信息是有关如何使用对象或如何做事情的。这类似于一个代码空间。
长期记忆中一个活跃的区域是短期记忆或工作记忆。工作记忆的内容是积极的,可被快速访问的。这样记忆内存量小,只有大约七个单位,这也取决于任务和测量方法。关于短期记忆的经典研究是Miller在1956发表一篇论文,恰当地称为《神奇的数字:7±2——我们信息加工能力的局限》( G. A. Miller,1956)。Miller对刺激的绝对判断进行了大量研究,如音调对听觉的刺激中或盐水溶液对味觉的刺激等。人类通常是能够区分七个水平单位维度的刺激。
Miller将这项工作扩展到对人的记忆的研究中,有这样一个实验描述,给被试呈现一系列的项目内容,然后要求他们回忆内容。他发现,处理这样的任务时,人的能力相似的,都是大约7(±2)个项目。对Miller论文的简单证明如图2.18所示。在这个“微型实验”中,有一个人机交互课程班的学生(N≈60)分配到一些记录卡片。教师口述一组随机数序列,序列长度从4位到13位的不用等。每次口述完成后,学生从短时记忆中提取信息将序列复述到记录卡片上。序列长度与正确率的比例如图中所示。序列长度为7的正确率约为50%。在长度5和9的值分别为90%和20%。参见本章末尾学生练习2-2。
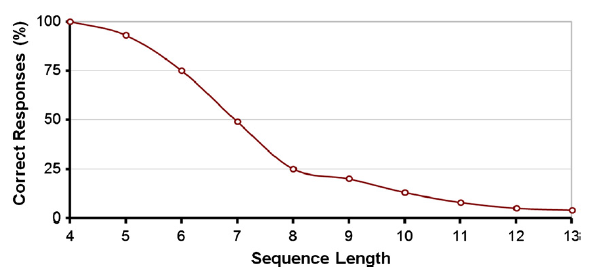
图2.18 短期记忆的测试结果
Miller把他的工作拓展到了揭示和分析简单但功能强大的大脑运作过程中:我们将多个项目关联成一个项目的能力。所谓组块是指人将一系列低级别的项目整合成一个单一的高级项目。他使用二进制数字描述了一个例子。例如,一个16比特的序列,如1000101101110010,将会很难记住。然而如果将序列拆分成四组,组块就成为了十进制数字,这种模式就很容易记住了:1000101101110010→1000,1011,0111,11,0010→8,11,7,2。Card等人(1983,36)给出的例子是BSCBMICRA。九个记忆单元,字母序列超出大多数人重复能力。但序列是类似于以下三组的三个字母序列排布的:CBS IBM RCA。呈现出这样包含三个组块的序列,只要人重新编码的速度足够快的话,记住这一串字母还是相对容易的。分块的过程大多是非正式和非结构化的。人类本能地建立分组递归层次结构,形成了大脑中复杂的记忆组织形式。
2.6语言
语言——允许人类交流的心智能力——是几乎所有人都普遍掌握的。值得注意的是,用语言交谈是与生俱来的,不需要后天的努力。小孩子在成长和发展的过程中学说话,理解交谈内容,都是在无意识的情况下进行的。然而,文字作为语言的汇编方式,则是经过努力后才具备的。学习文字需要努力,需要相当大的努力,需要多年的研究与实践。Daniels和Bright将语言和文字作了如下区分:“人类是由语言定义的;但文明是由文字定义的。”(Daniels和Bright,1996,p. 1)。这些话提醒我们,与文明相关的文化和技术水平是由文字系统带来的。事实上,人们使用的史前时期这个术语,可追溯到人类生命形成时期,从数百万年前到出现文字记录。以文字形式记录下的历史,开始于六千年以前。
在人机交互中,我们对于语言关注的兴趣点主要是在文字系统以及以文字形式进行交流的技术手段上。文本就是页面或显示器呈现的文字材料。研究其如何实现的这一课题也是人机交互研究人员遇到的复杂的困难和挑战,当然,这也是创造产品、支持文本输入的工程师和设计师们面临的挑战。虽然在人机交互中文本输入十分重要,但是我们的兴趣所在却是这是书面形式的语言本身。
表征和研究书面形式的语言一种方式是语料库——收集了广泛的文案样本,他们来源广泛,具有代表性的资源诸如报纸,书籍,电子邮件和杂志。当然,语料库无法精确涵盖和代表一种语言。文本采样过程受到一定的限制:这段样本是在什么时间框架下完成的?来自哪个国家?哪个地区?样本中的话题是什么?作者是谁?知名的语料库英国国家语料库(BNC),总共收纳了近一亿个样本。材料是书面英语,起始于20世纪晚期。所以采集分析工作从BNC开始,因为一般使用的英语,其精确程度往往不高,例如美国英语,日常用语,或者青少年发送短信息中的用语等。
为了促进研究分析的进行,语料库有时被缩减成一个词频列表,列表展示的是一些特有词汇以及它们在语料库中出现的频率。BNC中一个这样的约简列表包括约64000独特的单词,总共的使用频率可达到九千万次(Silfverberg,MacKenzie,and Korhonen,2000)。只有在预料库中出现频率大于等于三次的词汇才能被收录到列表中。使用最频繁的词是the,约占全部词汇量的6.8%。
图2.19包含若干个语料库的摘录,显示五个最常用的词和词,他们的排名为1000到1004。英文条目来自于英国国家语料库。里面也有法语的补充(New,Pallier,Brysbaert和 Ferrand,,2004),德语(Sporka等人,2011),芬兰语,英文短信,拼音短信(Y. Liu and Räihä,2010。芬兰的作品都是来自于芬兰的一家报纸数据库的文本,图尔库新闻报。英文短信条目是从10000条短信中收集的,发送人大多是新加坡大学的学生。短信是动态的,具有上下文敏感性的语言,这是代表了语言本质的一个很好的例子。英语短信的分类页倾向于上述限制。请注意,条目中不存在1-5个英文和英文短信的重叠。
图2.19右边罗列是拼音短信。拼音是自1958年制定的标准编码系统,使用拉丁字母和中文字符。条目是拼音标识,而不是词句。每个拼音对应表示的是括号中的汉字。条目来自于语料中的630000条短信,包含超过九百万个汉字。

图2.19 各种语言的单词频率表样本词汇
一些语料库的一个显著的特点是词性(POS)标记,依据词的类别给予相应的标签,如名词,动词,形容词。重要的是,词性都是上下文相关的,反映的是一个词在原文中用使用方式。例如,paint,有时是一个动词(儿童富有激情的绘画),有时是名词(油漆十分干燥)。词性标注是重要的预测系统,了解词的词性限制能够预测下一个词可能的词性(Gong, Tarasewich,和MacKenzie,2008)。
2.6.1冗余的语言
使用母语的人天生具有对语言统计的令人震撼的理解力。我们会自动插入被忽略或掩盖的文字(火腿和____三明治)。我们会预期文字内容(一张价值一千_____的画作),字母(questio_),或整个短语(生还是_______)。我们可能会问:既然人类能填补缺少的字母或单词,也许不需要的部分可以省略掉了。让我们进一步考虑一下。图2.20中的例子给出了一段文字的三处变化。原文摘录包含243个字符。在(a)部分,所有71个元音被删除,文本从而缩短了29.2%。许多词是很容易猜到的(例如,summr→夏天,thrgh→通过),还有一些需要一点努力才能猜到,这些文字的大意是明显的。它跟夏天【summr】,花园【grdn】,气味【scnt】都有很多联系。在(b)部分和(a)部分相似,只是每个单词的第一个字母都是原封不动的,即使它是一个元音。但是仍有62个元音去除了。破译单词的意思稍微容易了一些。(c)中给出的是原文,它是Oscar Wilde的长篇小说《道林•格雷的画像》第一段。如上所述,文本中的部分被去除还有很多其他的例子,但仍然可以被理解。短信是一个记录的例子。除了删除字符,记录是经常使用的。有许多方法可以使用,如利用声音(th@s→that’s,gr8→great)或发明缩写(w→with, gf→girlfriend, x→times)(Grinter and Eldridge,2003)。有个故事讲述了一名13岁的学生交给他的老师易用短信速记法写下的一整篇文章。尽管老师对此篇论文印象不深,但学生使用文字的基本原理是直接的、诚实的:速记法比标准英语更容易书写。如图2.21所示的一个例子。(a)部分给出了短文本。共有26个单词和102个字符(包括空格)。扩展的文本(b)包含39个单词和199个字符。减少量是富有戏剧性的:短信速记中少了48.7%的字符。当然,这与图2.20中的例子有所不同。例如,在这个例子中,标点符号和数字都被进行了编码。同时,速记短信是针对的一类特定用户群体的语言。而那个13岁孩子的老师显然不在这个群体中。
不幸的是,在书面文字中冗余词汇有着更阴险的一面。在写作中常见的问题就是多余文字的存在,但这种繁复的写作风格在很多著作中可谓凤毛麟角。Strunk和White的17条规则之一就是省略不必要的文字,并建议减少一些冗余内容,例如,“他是一个”改成“他,”或“这是一个…学科”改成“这个学科是”(Strunk和White,2000,p. 23)。在写作风格上的提示将在第八章中给出。

图2.20 Oscar Wilde的长篇小说《道林•格雷的画像》第一段:(a)元音删除(b)以元音开头的单词保持完整(c)原文

图2.21英语缩写:(a)短信速记(b)标准英语
2.6.2语言中的熵
如果语言中冗余内容是我们天生就知道呢,那么熵就是我们所不知道了——对即将出现的字母,单词,短语,理念,概念等的不确定性。显然,冗余和熵是相关的:如果我们移除已知的东西,那么剩下的就是我们所不知道的。上世纪50年代,Shannon 的字母猜测实验展示了一个书面英语中冗余和熵的示范(Shannon,1951)。(见图2.22)实验过程如下。被试被要求从头开始猜测短语中的字母。随着猜测的进行,短语逐渐一个词一个词地呈现在被试面前。结果记录在下面图中每个短语下方显示的横线上。破折号(“-”)表示猜测正确;单词表示猜测错误。Shannon 称第二行为“减少文本”。就冗余和熵而言,破折号表示冗余(已知的),而一个字母代表熵(未知的)。图2.22中有趣的观察发现是,错误在开始的时候是比较常见的,随着单词的进展而逐渐隐匿起来。统计性质的语言和被试的固有理解语言共同促进单词的猜测进度。

图2.22 Shannon的字母猜测实验
图2.22的字母猜测实验不只是让人好奇。Shannon的动机是量化英文信息理论内容中的熵。他指出,例如,在每个短语对应的两行线,它是可能具有相同的信息,良好的统计模型能够从第二个字母开始逆推出第一个字母。由于印刷英文的冗余(即破折号),通信系统只需要发送减少后的文本。原始文本可以使用统计模型进行恢复。Shannon还展示了如何计算印刷英文的熵。考虑到字母独有的频率,每个字母的熵是大约为4.25比特,考虑到已经使用了的字母,熵会减少,因为不确定出现的字母减少了。考虑到长期统计的影响(最多100个字母),Shannon估计印刷英文的熵大概有一比特,相应的冗余度为75%左右。
在本章的最后学生练习2-2还将看到相关内容。